Epidemia Covid-19 w Polsce
Epidemia zaczęła się w Chinach w 2019 roku. Nagle zaczęli umierać ludzie z dziwnym zapalenien płuc. Większość zmarłych to były osoby starsze. Zaraza wskutek podróżowania ludzi rozeszła się po świecie i zaczęła się pandemia czyli światowa epidemia. Słowo pandemia nie oznacza wysokiej śmiertelności, ale ogarnięcie epidemią wielu krajów świata.
Na początku epidemii liczba osób zarażonych rośnie w coraz szybszym tempie. Po czym część tych osób umiera. W zależności od wielu różnych czynników procentowy udział zgonów wśród osób zarażonych się zmienia. Prasa donosi, że we Włoszech zmarli stanowili 13,6%, w Nowym Yorku 8,8%, a w Niemczech 3,9%. Liczby się zmieniają. Bieżace dane można wyczytać ze strony Covid-19 -Panel ESRI Polska.
Rząd, przemysł, lekarze, emeryci i uczniowie się zastanawiają kiedy epidemia Covis-19 się skończy. Epidemiolodzy i matematycy próbują coś powiedzieć, ale wszyscy praktycznie zgadują. :-)
Od początku epidemii w Polsce patrzyłem na krzywe wzrostu liczby zakażonych.
Mając Excela pod ręką i nie ucząc w tym czasie studentów, którzy wygnani
zostali z uczelni wrzuciłem dane do Excela i to co odkryłem przedstawiam poniżej.
Na podstawie obserwacji, metodą prób i błędów znalazłem równanie najlepiej pasujące do charakteru przebiegu punktów w marcu 2020. Excel pozwolił obliczyć współczynniki równania czyli wzór, który w miarę dokładnie oblicza liczbę zachorowań i prognozuje liczbę zarażonych na przyszłość. Wzór na podstawie danych w marcu przewidywał z dokładnością lepszą niż 5% wykryte przypadki do połowy kwietnia. Potem wskutek działania restrykcji prawnych wzrost przestał przyspieszać i się mniej więcej ustabilizował.
Metoda prognozowania rozwoju epidemii.
Na stronach
COVID-19
można znaleźć grafiki jak poniżej.
Większość podawanych przez media wykresów pokazuje tak mniej więcej i zestawia
takie wykresy w różnych krajach i porównuje z rozwojem epidemii w Polsce.
Chyba tylko po to by osłodzić Polkom i Polakom cierpienie z powodu przymusu
kwarantanny, zamykania biznesu, usług i rozrywki, strachu przed pójściem do lekarza.
Część dziennikarzy bez wykształcenia matematycznego twierdzi, że rozwój epidemii
jest wykładniczy co jest nieprawdą, zarówno w Polsce - co wykażemy - jak i na świecie.

Uwaga: Gdyby przyrost był wykładniczy tj. według wzoru y = a * 2x
lub y = a * exp( dni/T ), to na tym wykresie punkty układałyby się na linii prostej.
Krzywa wzrostu wykładniczego w takim układzie współrzędnych zmniejsza swoje nachylenie
w czasie, więc czytelnik może się pocieszać, że epidemia wyhamowuje. Tak nie jest.
Kształt tego wykresu jest mylący.
Poniżej te same dane przedstawione w najprostszym układzie współrzędnych x-y. Od razu rzuca się w oczy, że na wykresie część punktów układa się wzdłuż krzywej o zmiennym nachyleniu, a potem układają się prawie w linii prostej.

Postarajmy się znaleźć najlepsze równania, które opiszą te dwie fazy rozwoju epidemii.
Przedłużenie takiej linii będzie PROGNOZĄ.
Faza kontrolowanej epidemii
Na poniższych wykresach będę używał współrzędnej x na wykresach jako liczba dni od początku epidemii. Ustaliłem, że dniem 'zero' jest 5 marca 2020. Z wykresów wynika, że od początku epidemii do 9 kwietnia narastanie liczby zakażonych przyspieszało, a potem szybkość narastanie się ustabilizowała - epidemia jest kontrolowana.
Po od 8 do 19 kwietnia punkty się układały, mniej więcej, wzdłuż linii prostej. Wobec tego można by zastosować wzór na linię prostą y = a* x + b, ale jeszcze lepszy jest wielomian trzeciego stopnia
y = a*x3 + b*x2 + c* x + d.
Krzywa według tego wzoru bardzo ładnie biegnie po punktach w zakresie dziesięciu dni.

Gdyby wierzyć tej linii dla następnych 5 dni to epidemia by przyspieszała i prognoza byłaby tragiczna - powyżej 13 tys. Prognoza na podstawie linii prostej wskazywała niższy wynik - prawie 11 tys zachorowań. Ale wykres zrobiony kilka dni później wykazał, że prognoza z wielomianu 3-go stopnia była przesadzona. Prognoza wskazywała, że w 50-tym dniu epidemii będzie ponad 13 tys zakażeń, a okazało się że naprawdę było poniżej 11-tu tys zakażeń.

Różnica między prognozą a rzeczywistością wyniosła 2 tys. - dość sporo. Na wykresie zaznaczono zielonym punktem ile wyniosła wartość rzeczywista w 55-tym dniu epidemii. Widać, że prognoza na 5 dni naprzód jest znacznie dokładniejsza. Ale znowu kropkowa niebieska linia z wielomianu prognozowała tym razem niższy wynik, gdy tymczasem cienka zielona linia prosta trafiła w zielony punkt.
Z powyższych wykresów i mojej praktyki przybliżania różnych danych doświadczalnych wielomianami wynika, że po pierwsze nie należy ekstrapolować przebiegu danych, a po drugie jeśli już, to nie dalej niż 20% długości przedziału, w którym mamy punkty. Czyli w tym przypadku nie dalej niż na kilka dni naprzód. Praktyka wskazuję, że dane należy przybliżać jak najprostszymi równaniami. Poniżej liczba zdiagnozowanych pozytywnych do 28 kwietnia 2020, przybliżona linią prostą.

Od ogólnie prostoliniowego przebiegu widać odchyłki w górę i w dół.
Aproksymacja czyli przybliżenie linią prostą łącznej liczby zdiagnozowanych
pozytywnie przypadków, daje wystarczająco dobre wyniki. Błędy aproksymacji
czyli odchyłki od linii trendu pokazano na wykresie poniżej.
Warto zauważyć łagodne przejście błędu poniżej osi po 55-tym dniu epidemii,
co może świadczyć o wyhamowywaniu epidemii lub zakłóceniach w systemie
diagnozowania - testowania. Wpływ częstości testowania na wykrywalność
zakażeń koronawirusem będzie omówiony dalej.

Na skali poziomej liczba dni od początku epidemii Covid-19 w Polsce tj. od 5 marca 2020r.
Znajdowanie wzoru na pierwszy etap epidemii
Pierwszy etap epidemii to gdy testowano i izolowano tylko chorych z wyraźnymi objawami Covid-19. Natomiast 80% osób zarażonych chorowało bezobjawowo i te osoby roznosiły wirusa wszędzie gdzie przebywały. W klasycznej teorii epidemii krzywa wzrostu zachorowań jest wykładnicza.
Po kliku łatwych sztuczkach z wykresami w Excelu stwierdziłem, że najlepsze przybliżenie danych uzyskuje się stosując wzór potęgowy y = a * xn. Excel potrafi nam znaleźć współczynniki równania potęgowego. Jeżeli liczbę sumarycznie pozytywnie zdiagnozowanych pokażemy w układzie podwójnie logarytmicznym to punkty od początku epidemii w Polsce do końca marca ułożą nam się wzdłuż linii prostej.

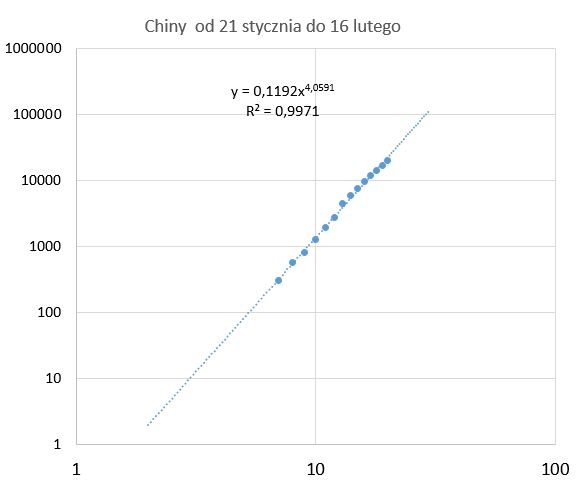
Na takim wykresie im wyższe jest nachylenie układających się punktów, tym wyższy wykładnik. U nas wykładnik wynosi około 3, a w Chinach y = 0,1192 * x4,0591 przy R2 = 0,9971
Na wykresie widać, że początkowo szło jak po sznurku - czerwona prosta, potem linia zaczyna się odchylać - zielona prosta. Równania obu linii można wyznaczyć metodą najmniejszych kwadratów dla obu zakresów punktów z wykresu. Jeśli się przyjrzeć punktom pod zieloną linią to punkty mają niewielkie odchylenia. Przybliżenie tej fazy pokazałem wcześniej
Na wykresie potwierdza się, że im wyższe jest nachylenie układających się punktów tym wyższy wykładnik. U nas wynosi około 3, gdzie X = data - 05 marca 2020 r.
y = 0,1293 * x3,0081, przy współczynniku korelacji R2 = 0,9995
Pochodna powyższego równania daje nam oszacowanie wzrostu liczby dziennych zachorowań w pierwszym etapie epidemii. Dane oficjalne z raportów MZ o dziennych zachorowaniach ze strony COVID-19 potwierdzają ten wniosek. Przebieg słupków na tym wykresie pozwala się szybciej zorientować czy epidemia sie rozwija, stabilizuje i wygasza.

Na rysunku widać, że do końca marca zachorowania, a właściwie pozytywne
wyniki testów, przyrastały przyspieszająco, a potem przy kilku wyskokach
zaczęły sie utrzymywać na średnio stałym poziomie.
Jednak widać także wyraźnie, że w kwietniu na średnio stałym poziomie
wykrywanych nowych przypadków jest zafalowanie. Jeśli policzymy słupki
to okres tej fali wynosi 7 dni. Świadczy to o cyklicznej pracy Sanepidu,
szpitali i laboratoriów. Nie wiem kto tu najbardziej jest winny.
Ludzie raczej nie zarażają się cyklicznie - chyba, że weźmiemy pod uwagę
chodzenie w niedzielę do kościoła.
Widać także, że gdyby nie te wyskoki związane prawdopodobnie z lokalnymi
ogniskami epidemii typu szpital, DPS lub kopalnia to krzywa by zaczęła
opadać. Czyli epidemia wśród 'zwykłych ludzi', czyli nie personelu medycznego,
wygasa bardzo powoli.
Śmiertelność
Po pierwsze defincja umieralności i śmiertelności.
Umieralność dla danej choroby to stosunek liczby zgonów do wielkości populacji.
Śmiertelność to stosunek liczby zgonów do liczby zachorowań na daną chorobę.
Oficjalne dane o śmiertelności dla Covid-19 podawane często przez Ministerstwo Zdrowia
opierają się o tę definicję. Ale według mnie powoduje to zaniżanie śmiertelności.
Oficjalne dane MZ podają śmiertelność jako stosunek sumarycznej liczby osób zmarłych do sumarycznej liczby zakażonych. Sumarycznie czyli od początku epidemii. Taka metoda raportowania śmiertelności jest dobra, ale po zakończeniu epidemii.
W tej metodzie początkowe wartości śmiertelności są zerowe, gdyż od momentu pierwszego
wykrycia zarażenia (4 marca 2020) do pierwszego zgonu (12 marca 2020) minęło 8 dni.
Prawidłowo powinno się liczyć aktualną śmiertelność krocząco. To znaczy jako stosunek
liczby zmarłych w pewnym odcinku czasu do liczby nowozakażonych w tym odcinku czasu.
To jest chwilowa albo aktualna śmiertelność. Jednak ten sposób też daje zaniżone wyniki
gdy rośnie codzienna liczba nowozakażonych.
Ze względu na wykrytą tygodniową cykliczność wykrywania nowozakażonych proponuję,
aby odcinek czasu wynosił tydzień. Takie uśrednianie zmniejsza fluktuacje
obliczonego wskaźnika.
Poniżej wykres przedstawiający obliczony wskaźnik śmiertelności w procentach dla
tygodniowego uśredniania. W aktualnym etapie rozwoju epidemii wskaźnik śmiertelności
waha sie wokół 6,6%.
Poniżej pokazano wyniki obliczeń według proponowanego wzoru, zgodnie z równaniem:
suma nowych zgonów przez 7 dni
śmiertelność = --------------------------------- * 100%
suma nowych zakażeń przez 7 dni

Według komunikatów Ministerstwa Zdrowia na temat przyczyn śmierci osób zakażonych koronawirusem przyczyną były na ogół choroby współistniejące. Na wykresie poniżej pokazano porównanie wieku osób umierających przed epidemią (2018) i podczas epidemii Covid-19. Z porównania wynika, że podczas epidemii stosunkowo więcej umiera osób w wieku 60-79 niż w normalnych warunkach. Świadczy to o tym, że osoby stare (80+) wcale nie są bardzej narażone od osób młodszych.

Dyskusja zasadności metody obliczania śmiertelności
Ze względu na fakt, że większość osób zarażonych przechodzi zarażenie bezobjawowo i nie wiadomo ile to jest dokładnie - szacuje się, że 80%, - to rzeczywista śmiertelność Covid19 w całej populacji zarażonych wynosi około 1,5%. (Stan na początek maja 2020 r.)
Taka śmiertelność jest wyższa od śmiertelności grypy HongKong. Ponad 6 mln chorych i prawie 6 tys. zmarłych to bilans tylko jednego sezonu grypy w Polsce w 1971 r. Śmiertelność ok. 0,1%. Ale... wtedy nie było testów genetycznych, więc jako chorych kwalifikowano osoby z objawami grypy.
Natomiast według danych WHO śmiertelność globalna na koronawirusa liczona z ogółu wszystkich zachorowań wynosi średnio 6,21% (1.923.280 zachorowań i 119.587 zgonów - dane z 13 kwietnia 2020 r.). Ale już 12 maja globalna śmiertelność wyniosła 6,83%.
Nie wynika to bynajmniej z braku respiratorów i gorszej pracy służby zdrowia, ale z błędnego obliczania wskaźnika śmiertelności. Ocenę radzenia sobie służby zdrowia z chorobą Covid-19 trzeba opierać na chwilowym wskaźniku śmiertelności, o którym powiedziano wcześniej.
Na wartość tak wyliczonej śmiertelności ma wpływ mianownik ułamka czyli liczba pozytywnie zdiagnozowanych, a na to z kolei ma największy wpływ liczba wykonywanych testów.
Wpływ liczby testów na wykrywalność
Na poniższym wykresie, na podstawie oficjalnych danych Ministerstwa Zdrowia,
pokazano jak w marcu i kwietniu 2020 liczba wykrywanych przypadków zależała
od liczby testów. Z ułożenia niebieskich punktów wzdłuż linii (dane w marcu)
wynika, że ta zależność jest bardzo silna, co mogłoby sugerować, że liczba
wykrywanych nosicieli koronawirusa zależała od liczby testów.
Jednak nachylenie tej linii równe 0,05 czyli 5%, świadczy o tym, że w marcu
wykonywano dostateczną ilość testów. I nie jest to tylko propaganda Ministra
Zdrowia.
Ta prosta zależność zniknęła w kwietniu gdy zwiększono możliwości testowania
przez laboratoria szpitalne i komercyjne. W kwietniu i maju punkty układają się
przypadkowo w postaci chmury z liczbą testów od 4,4 tys./dz. do 17,5 tys./dz.
i liczbą pozytywnych wyników od ok. 220 do 550. Kształt chmury świadczy o tym,
że wykrywano około 370 nowych przypadków dziennie niezależnie od liczby
wykonywanych testów.
Niestety Minister Zdrowia nie ujawniał danych na temat dokładności zakupionych testów tzn. procentu fałszywych dodatnich i fałszywych ujemnych wyników. Mimo to wykrywalność nosicieli wynosząca 5%, może świadczyć o wystarczającej na tamtym etapie - pierwszy miesiąc epidemii - ilości testów i rozsądnym sposobie wyboru osób do testowania.
Brak rutynowego badania na obecność wirusa wśród osób zmarłych może zaniżać rzeczywistą obecność tego wirusa w całej populacji.

Po najnowsze dane zapraszam do Wikipedii.
Objaśnienia do tworzenia wykresów
Punkty na wykresach to zawsze dane doświadczalne, w naszym wypadku dane podawane przez MZ
lub Sanepid.
Linie ciągłe lub przerywane to linie obliczone na podstawie równania lub narysowane 'ręcznie'
w programie graficznym.
Niestety w programie Excel nie ma aż tak wielkich możliwości, żeby nanieść kilka linii trendu
na jednym wykresie.
Dokładnie ujmując - można to zrobić, ale bardzo kombinując.
Linię prostą tak poprowadziłem, aby jak najlepiej (na oko) przebiegała przez punkty
w dolnym zakresie dat. Excel też by taką linie narysował, gdyby brał pod uwagę tylko
punkty od 11 dnia epidemii np. do 12 kwietnia.
Jak się patrzy na punkty i czerwoną linię to widać gdzie (kiedy) punkty zaczynają się odchylać
od poprzedniej tendencji czyli wzoru potęgowego. To odchylanie ma jakby dwie fazy.
Współczynniki we wzorze są obliczone przez program Excel metodą najmniejszych kwadratów.
R2 to jest współczynnik korelacji. Wskazuje jak dobrze punkty się układają na linii zgodnej z jakimś równaniem.
Na naszych wykresach na początku jest to równanie potęgowe, a potem równanie liniowe.
Większa wartość R2 jest tylko potwierdzeniem, że jedno z równań lepiej niż
inne przybliża dane. Im R2 jest bliższe jedności, tym lepsza jest korelacja.
Dla R = 1 punkty dokładnie leżałyby na linii.
Na wykresie zachorowań w skali dwulogarytmicznej wzór jest typu: y = a * xn, gdzie n może być liczbą rzeczywistą, dodatnią. Rzeczywistą, bo nie tylko liczby całkowite wchodzą w grę, a dodatnią i większą od 1, bo krzywa zachorowań rosła i wykrzywiała się do góry. Gdyby krzywa rosła, ale coraz wolniej, to n by było z zakresu: 0 < n < 1. Dla n = 1 krzywa była by prosta.
Excel ma słabe opcje robienia wykresów. W Wikipedii moduł graficzny 'Wykres' pozwala na lepsze opisywanie osi w układzie logarytmicznym.

Wybrany podwójnie logarytmiczny układ ma właściwość zagęszczania punktów dla większych wartości. Poniżej wykres zrobiony dla przypadków po 100 dniu pandemii w Polsce. Widać tu różne okresy rozwoju i wytłumiania liczby zachorowań. Skrajny fragment dla dwusetnego i dalszych dni wyraźnie odchyla się od linii prostej. Świadczy to o niekontrolowanym rozwoju pandemi Covid-19. Wykładniczy wzrost to początek katastrofy. Chorzy za dwa tygodnie (pisane 9 październka 2020) będą umierać w namiotach rozstawinych przy szpitalach. Na początku listopada bywało, że pacjenci umierali w karetce w kolejce na przyjęcie do szpitala.

W arkuszu kalkulacyjnym zastosowaliśmy metodę najmniejszych kwadratów, która w Excelu nazywa się linią trendu to znaczy, że w Excelu linia trendu jest obliczana metodą najmniejszych kwadratów.
Bardzo upraszczając polega to na tym, że współczynniki a i n tak się dobiera, aby uzyskać minimum sumy kwadratów odchyleń. A jeszcze bardziej upraszczając współczynniki równania tak się dobiera żeby linię dogiąć do punktów.
Problem polega na tym, że nie można tego ściśle rozwiązać, gdy jest więcej punktów niż współczynników w równaniu aproksymującym.
Metoda najmniejszych kwadratów ten problem rozwiązuje przez założenie, że jest możliwy kompromis. Tu się lekko dognie, tam pozwoli żeby linia nie biegła dokładnie przez punkt i to dotyczy wszystkich punktów, ale mniej więcej krzywa przebiega w pobliżu punktów, raz punkty są wyżej raz niżej.
Uwaga ogólna: To człowiek, badacz ocenia, czy jego równanie pasuje do danych, a konkretnie czy dostatecznie dobrze pasuje do danych biorąc pod uwage błędy doświadczalne, przypadkowe i systematyczne i powtarzalność wyników eksperymentów.
W Wikipedii znajdziecie odpowiednie wzory do obliczenia dla przybliżania linią prostą oraz modele matematyczne epidemii - zasady są proste, ale równania jakie potem wychodzą już proste nie są.
Próba wyjaśnienia odkrytej niezgodności ze wzrostem wykładniczym
W wikipedii napisałem notę "Przyrosty procentowe, czarna linia 17% i szara 7%, są zgodne z teorią o wzroście wykładniczym zachorowań w epidemii. Inne kształty przebiegu, takie jakie występują na tym wykresie, świadczą o nieprawdziwości modelu wykładniczego dla epidemii wśród istot inteligentnych."
Nota odnosiła sie do wykresu Pandemia_COVID-19_w_Polsce#Polska_i_państwa_sąsiednie.
Jeden z doświadczonych redaktorów Wikipedii skasował tę notę.
Był to komentarz do not 1 i 2, które mówiły o liniach wzrostu procentowego, który nijak się ma do rzeczywistego rozwoju tej epidemii w początkowym etapie - zwykle około miesiąca. Otóż gdyby epidemia rozwijała się jak wśród bakterii - ogólnie organizmów niemyślących - to organizm taki jak ma okazję to zaraża np. dwa kolejne organizmy. Szybkość wzrostu zarażonej populacji zależy od tego ile czasu zajmuje zbliżenie się do zdrowego organizmu i zarażenie. Na ogół zależy to od dyfuzji w cieczy i ruchów Browna. Tak uwarunkowany wzrost populacji zarażonej opisuje się wzorem wykładniczym.
y = 1,3x albo y = 2x albo y = exWartość przykładowa 2 to współczynnik reprodukcji R0, który mówi że każdy organizm zakażony wirusem może przekazać go dwóm kolejnym organizmom.
Na wykresie w układzie półlogarytmicznym jest to linia prosta.
Stąd tradycyjnie przebiegi epidemii przedstawia się na takim wykresie.
Ale taki wykres jest mylący bo wypłaszczanie krzywej wcale nie świadczy
o spowolnieniu rozwoju epidemii. W gruncie rzeczy taki wykres służy do
epatowania publiki. Z takiego wykresu oko ludzkie tylko odczytuje, że
w Chinach albo USA jest więcej zakażeń. Nic więcej z wykresu nie wynika.
Dopiero gdy pokazuje się dla różnych krajów przebiegi w przeliczenieu na
milion mieszkańców to można wnioskować jak kraje sobie radzą z epidemią.
Natomiast wśród istot inteligentnych, wiedzących co to jest epidemia i wiedzących, że osoba zakażona zakaża inne osoby obowiązują reguły życia społecznego. Jedna reguła jest taka: jeśli jestem chory to zakażam przy kontakcie z innymi osobami. Zakażanie nie jest dobre dla ludzi, nie chcemy żebyśmy my i inni byli chorzy. Więc jeśli wiem że mam objawy choroby to nie powinienem się kontaktować z innymi. Tak robi osoba inteligentna. Takie działanie łamie „zasady” jakie są wśród organizmów nieinteligentnych i wtedy cała matematyka rozwoju wykładniczego się załamuje. Świadomość jakie są objawy choroby i wykrycie ich (np. po kilku dniach od zarażenia) u siebie powstrzymuje dalsze zakażenia. Natomiast osoby zakażone, ale bez objawów dalej zakażają inne osoby.
W Chinach na początku epidemii brak było informacji o objawach i że to nie jest kolejna odmiana grypy. Wtedy wykładnik potęgi wynosił ok 4. W Polsce gdy epidemia już do nas trafiła społeczeństwo było poinformowane o objawach (np. krótkotrwała temperatura 38°C), wiedziało że jest to groźne więc dość szybko ci co mieli objawy wiedzieli, że powinni się powstrzymywać od kontaktów. Dodatkowo Rząd wiedząc (może nieświadomie), że dzieci przechodzą zarażenie bezobjawowo odciął tą część populacji od możliwości roznoszenia wirusa. To spowodowało, że wykładnik przy potędze w Polsce wyniósł 3.0 patrz romek.info/test/Prognoza3.html są tam ilustracje.
Reasumując, moje uwagi w nocie 3 uważam za istotne. Natomiast brak objaśnień linii 15% i 5% przez autora wykresu uważam za błąd edukacyjny.
The End
30 kwietnia 2020r. Uwaga: niektóre wykresy są aktualizowane na bieżąco.
ciąg dalszy może nastąpi
Świetny artykuł o możliwych strategiach ograniczania skutków epidemii koronawirusa
Jest tutaj po polsku
Warto przeczytać mimo, że długi.
Aktualizowane na żywo dane wraz z wykresami o rozwoju epidemii Covid-19 w Polsce



 Aktualizacja danych na wykresie 10 sierpnia 2020r.
Aktualizacja danych na wykresie 10 sierpnia 2020r.



{kind=link}